

Nvidia: The Next Inflection Point
Nvidia: The Next Inflection Point
Deep Dive

Edited by Brian Birnbaum.
1.0 An Innovator´s Dilemma
2.0 Nvidia´s Software Moat and Operating Leverage
3.0 The Threat of Hyperscalers
4.0 Financials 5.0 Valuation 6.0 Conclusion
1.0 An Innovator´s Dilemma
Nvidia´s monolithic approach to chips has an expiry date.
Nvidia is by all means a formidable company and I have a deep admiration for it, but if my view of the semiconductor industry is correct, it is currently headed for disruption. Nvidia focuses on making monolithic chips, in which all the components are crammed into a single piece of silicon and as we move towards smaller process nodes, these chips are getting exponentially harder to make. Nvidia excels at managing this complexity and continues to deliver the world´s top GPUs today, but the path it is currently on is a clear example of the Innovator´s Dilemma: although the margins stemming from its current monolithic approach are phenomenal, the ground is breaking up underneath the company´s feet as the industry shifts towards chiplets.
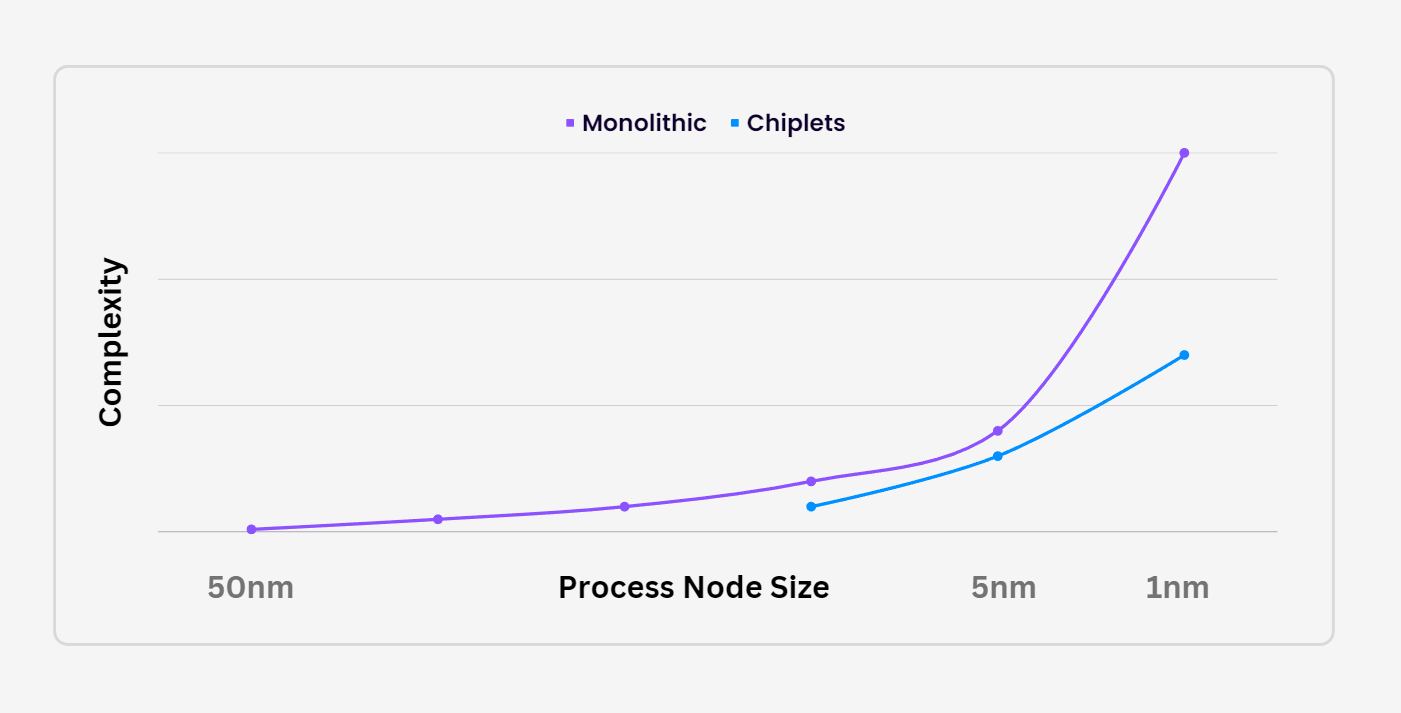
The chiplet approach consists in breaking down a processor into smaller, modular components, manufacturing them separately and then interconnecting them to form a complete processor. This approach tends to deliver better yields because if you mess up the production of one chiplet, you do not have to throw the entire chip away. Ultimately, this enables firms that pursue chiplet-based architectures to deliver more performance for less, circumnavigating the “end” of Moore´s Law. However, the chiplet architecture is not all that easy to apply to GPUs, since they bring about higher levels of latency. When you break down a processor into chiplets, the information takes longer to move around and so the scenario is not black and white.

In the domain of AI, which is essentially powered by GPUs, latency is king—or rather, the lack thereof. The entire stack goes up or down in value depending on how quickly and thus timely it is able to generate insights. It is far easier to optimize latency in monolithic chips, since all the components are closely integrated and thus, information can move around much quicker than otherwise. This is why Nvidia continues to franchise its way through increasingly monstrous chips and continuously pours out differential innovations like computational lithography. Every step the company takes in this direction, makes it much harder for lagging competitors to catch up. Margins and business volume go up, as Nvidia continues to securely float off into the clouds, perhaps making it somewhat complacent (?):
“We are not adverse to chiplets, but we are really good at making big dies, and I would say that I think we were actually better with Hopper than we were with Ampere at making a big die. One big die is still the best place to be if you can do it, and I think we know how to do that better than anybody else. So we built Hopper that way” - Jonah Alben, Senior VP of GPU Engineering at Nvidia, seemingly exhibiting a rather typical attitude of a company subject to the Innovator´s Dilemma in this interview.
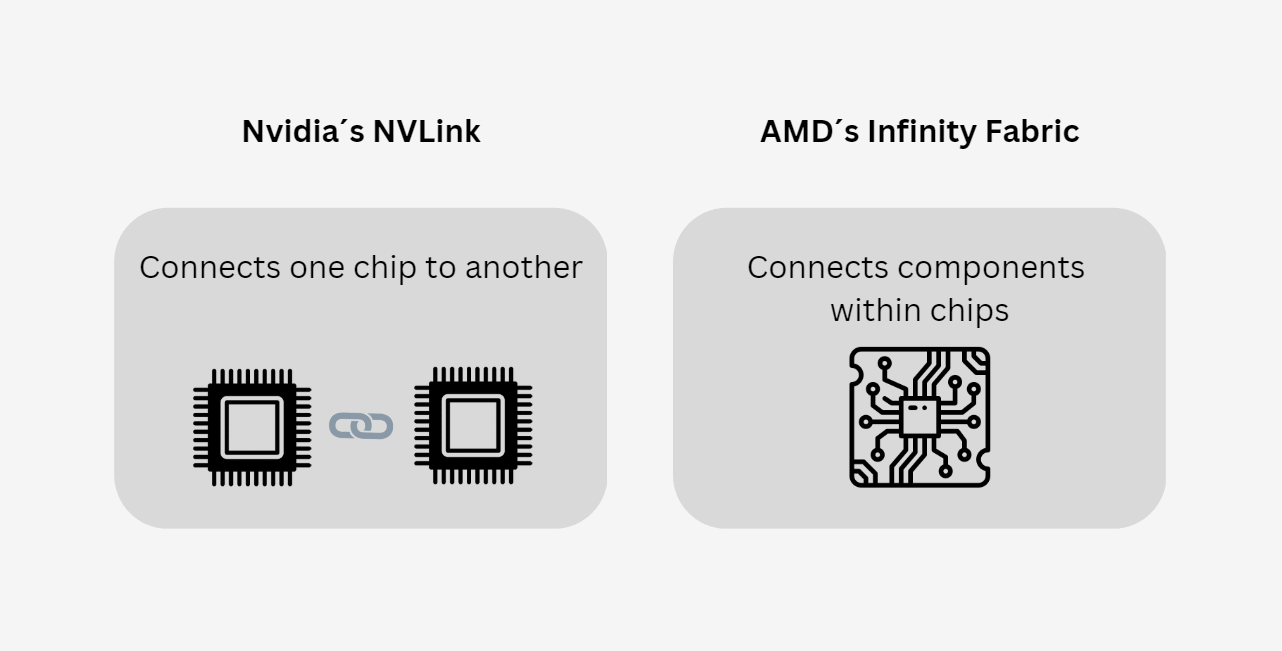
Going forward, therefore, it is a matter of whether chiplets in GPUs can be connected so that latency levels are acceptable or even negligible to customers, within a given price to quality ratio. This is by no means guaranteed and whether Nvidia gets disrupted or not very much depends on how this works out. AMD has taken considerable market share from Intel since 2016 thanks to its chiplet-based architectures and it has now set its sights on the GPU space. AMD uses a proprietary technology known as Infinity Fabric to connect chiplets and it has been fine tuning it since. The performance of AMD´s CPU engines have increased in lockstep with Infinity Fabric´s latency reductions with every new generation launched.
As I discussed in my AMD deep dive, the company is “cross pollinating” its CPU and GPU divisions, so that the key lessons in the CPU front can be applied to GPUs. Thus, whilst Nvidia is on relative terms on a sustained path towards meaner monolithic chips, AMD is on a sustained path towards connecting components better, no matter what the components may be. As the complexity of cramming everything into a silicon die continues to rise exponentially, being stuck on the monolithic path is perhaps not the best strategy and Nvidia is not showing much signs of pivoting, other than some interesting research papers in the last few years:
“MCM-GPU: Multi-Chip-Module GPUs for Continued Performance Scalability”. published in 2019.
Nvidia has a technology to connect components called NVLink which it has nonetheless only used to connect processors and not components within processors. Now in its fourth generation, NVLink connects processors at up to 900 GB/s, whilst Infinity Fabric´s current generation seems to work up to speeds of 800 GB/s. In terms of the speeds at which these two technologies can move information around, they are roughly on par. The question is, can Nvidia repurpose NVLink to connect components too? Reasoning from first principles, I speculate that connecting components within a processor is more complicated that connecting processors, since there are many more points of friction in the former case for latencies to accumulate, so perhaps pivoting NVLink to chiplets will not be that easy.
Currently, the world´s most impressive AI models are being trained on Nvidia´s A100 GPU. In datacenters, many of these GPUs are connected via NVLink to deliver the immense computational power required to bring to the world models like ChatGPT, so indeed the above observations are quite far removed from the mainstream narrative. However, I do believe that unless Nvidia shifts to chiplets, it will get disrupted soon. On the other hand, there are some interesting datapoints that counter the idea that Nvidia could get disrupted by chiplets:
Nvidia announced its Grace CPU in April 2021, designed for use in high-performance computing (HPC) and artificial intelligence (AI) workloads. In turn, the Nvidia Grace Hopper Superchip consists of a Grace CPU connected with an H100 GPU (announced in May 2022) via NVLink Chip-to-Chip, which extends NVLink´s functionality to enable the connection between any type of Nvidia processor. In the company´s words: “this enables the creation of a new class of integrated products with NVIDIA partners, built via chiplets, allowing NVIDIA GPUs, DPUs, and CPUs to be coherently interconnected with custom silicon.”
As Nvidia navigates the changing computing environment, I believe that it will be “forced” to default towards inter-connectivity in its products. As I discussed in my AMD deep dive, I believe that AI is going to force the industry to blur the distinction between C/GPUs, creating products that bundle up different compute engines to enable novel functionalities. This could have Nvidia naturally gravitating towards chiplets before it gets disrupted, or in their absence, higher level expressions of chiplets as is the Grace Hopper Superchip. The creation of NVLink Chip-to-Chip is telling.
AMD´s RDNA3, its first chiplet based GPU, has not been performing so well in the market. Firstly, this seems to be due to the low performance of RDNA3 versus Nvidia´s offerings and secondly, I believe it may also have much to do with Nvidia´s distribution moat (next section). It would be strange for AMD to nail the move to chiplets on the GPU front from scratch, but RDNA3 shows that it will not be that easy to displace Nvidia, which is optimizing its monolithic chips to phenomenal extents.
Nvidia has a large software moat, which gives it a considerable advantage on the distribution front. I will explore this in depth in the next section.
2.0 Nvidia´s Software Moat and Operating Leverage
Nvidia has a history of multiplying its operating leverage via software. It is likely about to do so again.
Nvidia has a phenomenal software moat which stems from its widely adopted programming model called CUDA (Compute Unified Device Architecture), launched in 2006. Folks do not dwell on the technical specifications of a given GPU, but rather want to get their application going as fast and as cheaply as possible. When coding a particular deep learning model, for instance, you just want to be able to effortlessly deploy it on a GPU for training. CUDA enables you to do that and if a GPU is not compatible, it is often not worth the hassle: naturally, CUDA only supports Nvidia GPUs.
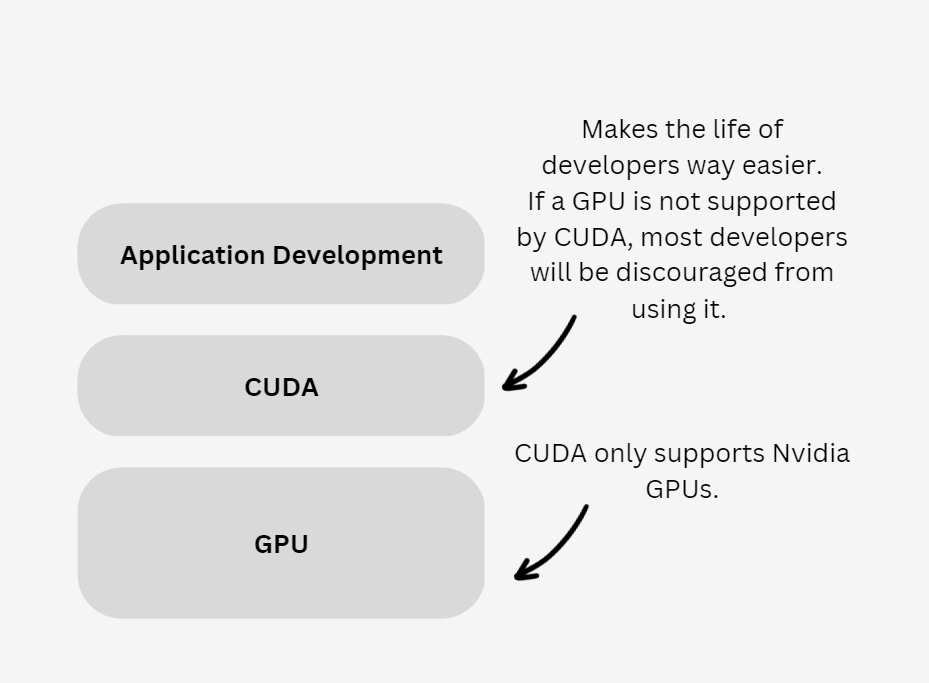
CUDA thus gives Nvidia a distribution advantage, whereby for the average CUDA user to embrace alternative hardware from a competitor, it must be quite a bit better than Nvidia´s offerings, because the user will experience some additional pain in deploying his/her code on the new hardware. Since CUDA essentially sits at the lowest level of a developer´s stack, it serves as a gateway for the deployment of additional services that make life easier for developers and organizations. Nvidia has leveraged this vantage point to launch a growing suit of software offerings, with Nvidia Omniverse and Nvidia AI Foundation being two of the more notable example. It has also launched Nvidia DGX cloud in March 2023, which in the company´s words:
“ … provides dedicated clusters of Nvidia DGX AI super-computing, paired with Nvidia AI software. The service makes it possible for every enterprise to access its own AI supercomputer using a simple web browser, removing the complexity of acquiring, deploying and managing on-premises infrastructure.”
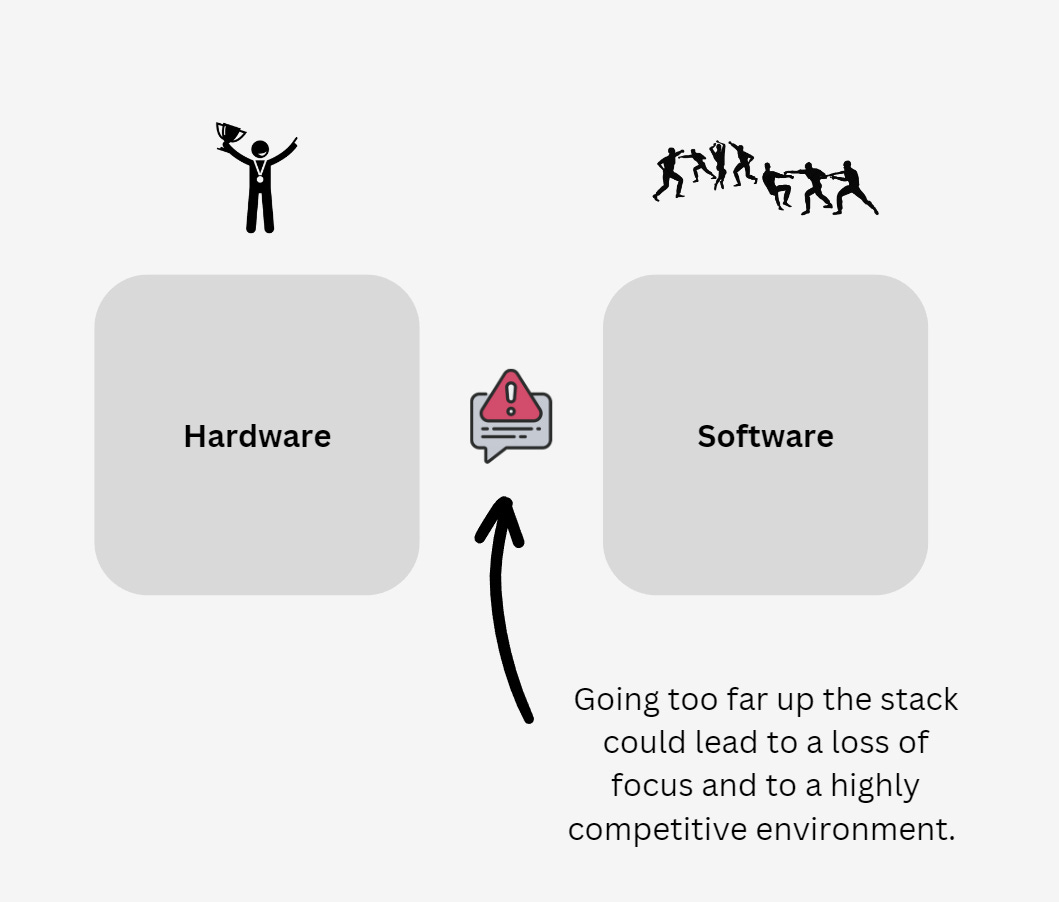
Whilst the upside for Nvidia down the software path is unlimited, it begins to somewhat cloud the company´s competitive landscape. Nvidia is currently undisputed on the hardware side and this is what gives the company its financial buoyancy, but as it moves up the stack it is bound to find highly specialized software companies that do not have their attention split between hardware and software. For instance, Nvidia Omniverse enables organizations to create digital twins and this sets it to compete against Palantir, which is focused exclusively on the development of digital twins for organizations.
The above example applies to all of Nvidia´s software as it moves up the stack and gets further from the hardware layer. However, seen from a probabilistic lens, although many of the initiatives will fail, some of them will succeed and will likely become AWS-like business segments for Nvidia: so long as the company is able to allocate capital prudently to the software side without losing track of the hardware side. Jensen Huang has recently been talking about an “AI Factory”, that gives organizations the tools they need to embrace AI. If they can develop CUDA-like tools that sit at the lower levels of the stack, it could be a great success.
To illustrate how the above can play out, consider the following case. After CUDA´s launch, Nvidia´s gross margins starting going up speedily: before 2006, GPUs were used just for gaming but with CUDA it became easier to use GPUs for an ever growing range of complex computational tasks that created far more value than gaming. This enabled Nvidia to design and sell more complex compute engines, which naturally came with higher margins. Some say it was luck, but Jensen Huang talks about CUDA´s development as something rather deliberate and arduous. CUDA effectively multiplied Nvidia´s operating leverage overnight, enabling it to channel its expertise into much higher margin domains.
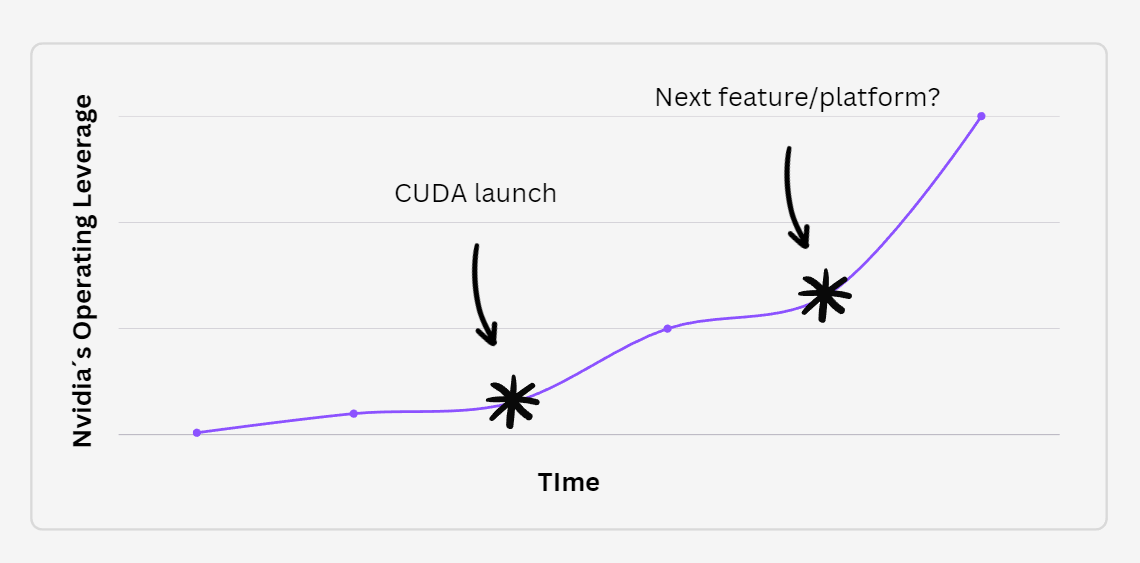
CUDA has since become a network upon which further layers of abstraction can be built, that connects millions of developers across the globe and so the question is, as we move into the world of AI, is there a new feature in Nvidia´s pipeline that can similarly augment the company´s operating leverage without it venturing too far out from the hardware shores? The answer to this question, assuming continuity on the hardware side, is what will determine the magnitude of shareholder returns over the next decade. The hardware can pay off on its own, with exploding computational requirements, but software will grant the non-linear increase in operating leverage as it has in the past.
This is what the market is trying to put a finger on with all the AI hype.
3.0 The Threat of Hyperscalers
Hyperscalers control distribution and thus, have the upper hand. Nvidia´s software moat acts as a great buffer, however.
Hyperscalers deliver the end product of the stack to consumers, so they control distribution. Chips are an essential component of the stack but as mentioned in the previous section, consumers only care about getting their apps running cost-effectively. A great chip can under-perform a more mediocre one if the latter is deployed in a sufficiently beneficial environment. For instance, if upgrading to the latest chip requires a developer to go through a painstaking code update, he/she will at some point prefer the mediocre hardware upgrade that involves a seamless update.

Hyperscalers know their environments to an extent that pure semi companies do not and hence, are able to yield incremental hardware updates that leverage the above dynamic. This is a meaningful form of alpha, as seen by the growing prominence of Amazon´s Graviton, which is simply a chip that AWS designs for itself. What this means for semiconductor designers is that they simply have to be better: they are going to have to differentiate their chips to the extent that hyperscaler engineers deem them worthy enough to interrupt their vertical integration endeavors.
“ … moving to Graviton2 means little to no code changes so that customers can quickly and easily migrate their workloads to access the best price performance in Amazon EC2.” - Amazon Q3 2021 ER transcript.
In this sense, Nvidia´s software moat acts as a great buffer. Indeed, hyperscalers do deliver the end computation, but developers interact directly with the GPUs via CUDA. For every developer that is dependent on CUDA, hyperscalers have to make room for a few Nvidia GPUs, shrinking the alpha of their integrated offerings. AMD, on the other hand, does not have such a cushion and is left to muscle its way into the datacenter by sheer out-performance. Naturally, this dynamic is relative and in practice, will play out depending on different sensitivities of the value chain.
On the other hand, hyperscalers have their attention split all over the place. They exist within organizations that perform other functions (Amazon is an commerce platform, Google a search engine, Apple a luxury hardware company) and despite popular belief, these companies cannot do everything. An exclusive focus on semiconductor design is likely to yield better chips over the long run. This dynamic can be observed in Amazon´s music and video offerings, for example: they are competitive, but cannot quite durably out-compete other highly focused players in the respective spaces.
4.0 Financials
Nvidia has exhibited some fantastic capital allocation over the last decade.
The economic slowdown is taking a toll on the company, with gross and operating margins slumping over the last year, but this is happening to companies in the sector across the board: it does not reflect any structural deterioration. What has caught my eye on the financial side, however, is how Nvidia ramped up its debt issuance during 2021-2022 inclusive. Over the previous decade, Nvidia only issued debt in 2014 and 2017 and then fully leveraged the low interest rates during the pandemic to fill up its war chest. Excellent capital allocation in hindsight, with rates shooting back up soon after the last emission.
Despite the company leveraging up in this manner, the balance sheet is still strong, with total cash and ST investments just above long term debt and covering 69% of total liabilities. Thus, Nvidia seems to have acted prudently when presented with this opportunity. Cash from operations has taken a hit over the last year, trailing the decrease in the top line and margins, but still funnels plenty of cash into the company for the purpose of longevity. Downturns do occur, but the demand for computing will be much higher in the future and so long as Nvidia continues to provide the leading supply, the financials will continue to improve. Particularly so if they find a new point of leverage, as explored in section 2.0.

5.0 Valuation
The valuation seems overextended at present, but the focus of long term shareholders should be elsewhere.
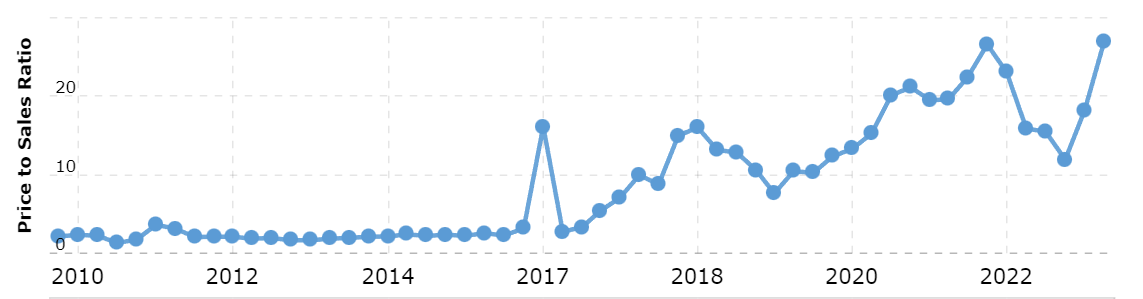
The price to sales ratio is often looked down upon, but I find that it is an accurate measure of optimism when it comes to companies with highly malleable income statements. Nvidia´s income statement could change any day now - be it from a disruption on the hardware side or from an operational breakthrough on the software side. With a price to sales ratio of ~26, the market is not amiss of the company´s potential upside and there are many calling out its overvaluation, but I have some second level thoughts.
In December 2001, Nvidia traded at $5/share with a market cap of approximately $12.3B. At the time, the shares traded at a price to sales ratio of 16, but have since gone up 57 fold in value. It is striking to see that, if you had bought in at the rather lofty valuation in 2001, you would have endured an 80%+ drop over the next couple of years, but then you would have likely made a fortune over the next two decades. In this particular example, the evolution of the fundamentals far exceeded the expectations of the most optimistic back at the time.
I believe that as we stand, the same framework can be applied. If Nvidia gets disrupted on the hardware side, a hypothetical investment initiated at a very prudent price is going to fail anyway. On the other hand, if the company continues to dominate on the hardware side and finds a new CUDA-like operational lever for the age of AI, the upside is quite large even from the current optimistic P/S ratio. The demand for computing will be exponentially higher in 10 years time than it is today and a leading position in the computing market will also be worth exponentially more.
Buying a stock when everyone is very excited about it is definitely not my style, however and I much prefer to buy in when everyone thinks it is a terrible idea. But it is true that in companies of this nature and especially if you are a long term shareholder, focusing your energy on determining whether the stock is 50% overvalued or not is rarely worth the effort. On the other hand, attempting to determine whether the fundamentals can evolve explosively again over the next decade usually pays off quite handsomely.
6.0 Conclusion
I need more clarity on the hardware side.
Although Nvidia has been moving towards connecting chips between them for some time, I intuitively feel that staying ahead is going to require a harder pivot at some point. I admire Jensen and consider him to be a modern Renaissance man, but I cannot quite read how he is thinking about moving down the curve of Moore´s Law, other than continuing to produce monolithic chips. If I were a shareholder, I would be especially vigilant of this dynamic, which as mentioned in section 2.0, I believe will rear its head as Nvidia is compelled to connect different compute engines to satisfy the rapidly changing computational needs of AI.
On the software side, Nvidia has limitless upside and especially as AI becomes more of an indispensable tool for organizations to thrive. However, by moving up the stack from its CUDA foundation it will encounter plenty of highly specialized firms and it risks fracturing its attention and resources. To succeed in this domain, I believe that Nvidia needs to find an AI-enabling tool that does not sit too high up the stack from CUDA, so that it can then delve in higher abstractions without losing focus and staying anchored.
I currently lack sufficient clarity on the hardware front. Further, Nvidia is perhaps too mature of a company for me to invest in, given the nature of my portfolio. However, having learned about the company in depth is beneficial to my understanding of the semiconductor space and particularly so as an AMD shareholder since 2014. I believe chiplets are the path around Moore´s Law and that although it will not be easy for AMD to take GPU share, it is well positioned to do so. But the folks at Nvidia are certainly not dumb.
Lastly, I believe that we continue to move into a world in which we simply do not have enough chips. Humanity´s core wealth generation mechanism consists in processing information to unlock insights and I do believe that the market will grow enough over the next 10 years for there to be plenty of space for many companies. Meanwhile, I continue to look for winning product roadmaps.
Until next time!
⚡ If you enjoyed the post, please feel free to share with friends, drop a like and leave me a comment.
You can also reach me at:
Twitter: @alc2022
LinkedIn: antoniolinaresc
Fantastic deep dive
I think work like this, the time invested in a project like this should be commended. Thank you for putting it together. I have some strong views and criticism though as I believed it's been influenced by AMD talking points rather than actual fact gathering. My comments should not take away from the effort, they are words of a many years shareholder.
“I do believe that unless Nvidia shifts to chiplets, it will get disrupted soon.”
AMD has been telling the world chipsets are the wave of the future for years. Yet their performance in head to head GPU markets illustrates where they be: they continue to lose market share. You only have a better widget if people want it, and that has yet be proven in the GPU space.
“As Nvidia navigates the changing computing environment, I believe that it will be “forced” to default towards inter-connectivity in its products. “
Not a bold claim. Nvidia invented Nvlink in 2014 and introduced it in 2016, bringing production volume, high speed interconnects to market with P100 GPUs well before AMD had infinity fabric in a shipping product. Nvlink technology linked Nvidia’s GPUs to IBM’s “Power” line of CPUs 7 years ago. Today Nvidia is on the cusp of introducing the Hopper+Grace superchip. So when you say “forced” you’re using pejorative language to make Nvidia seem out of step or behind. They're clearly not.
Understanding of CUDA software stack is not exhibited here. No description of how it become ubiquitous or why competitors were sitting on their hands while Nvidia was investing here for more than 10 years with little notice. Now it’s everywhere and competitors are whining about a “lock” on the industry. That’s nobody’s fault but companies like AMD and Intel who thought Nvidia was barking up the wrong tree.
“Nvidia Omniverse enables organizations to create digital twins and this sets it to compete against Palantir, which is focused exclusively on the development of digital twins for organizations.”
Very cursory understanding here. Palantir is a data analytics company, Nvidia is an accelerated computing platform company. I can nearly guarantee Palantir is using GPUs everyday. What Nvidia is building in Omniverse is a Virtual Digital Twin for collaboration, duplicating real life down to the nut and bolt, Planters work is quite different from what I understand.
“is there a new feature in Nvidia ́s pipeline that can similarly augment the company ́s operating leverage without it venturing too far out from the hardware shores?”
Nvidia is building an AI platform. That is the value. The more it’s used the more value is created.
Your section 3 is a grand blend of buzzwords and apparent misunderstanding. You may have a valid headline but the argument and data aren’t close to backing up your point.
Section 5 on the other hand. Really good long term perspective on the company. Bravo
“admire Jensen and consider him to be a modern Renaissance man, but I cannot
quite read how he is thinking about moving down the curve of Moore ́s Law, other than
continuing to produce monolithic chips. “
Jensen has said many times improvements in SOTA acceleration will come from a combination of both hardware and software. A recent example is the open source chatgpt model released last week in conjunction with hugging face with 2B parameters (opposed to GPT4s ~1T). The model delivers very strong results at a fraction of the cost budget. And the idea of open sourcing these results guarantees creative minds all over the world will work on and improve it.
“I believe that Nvidia needs to Find an AI-enabling tool that does not sit too high up the stack from CUDA”
If you paid attention to their developer side you would see this is exactly what they do. They provide many tools and techniques to the AI community to allow the community to add the "finished goods" value. This is the same model they’ve successfully employed with Game Developers and the Professional Graphics Industry for decades.